Содержание
Глоссарий
chunk - кусок файловой системы, btrfs размечает не диск, а chunk'и внутри раздела. Причем разметка выполняется по мере необходимости. Т.о. на разделе, где только что создана btrfs, большая часть пространства раздела остается не размеченной.
leaf - лиана, ветка метаданных, inode, в неё пишутся метаданные описывающие содержание chunk'ов и мелкие файлы.
лист - кусок чанка или сам чанк, туда пишутся данные.
Описание
Основные возможности btrfs (реализованные и планируемые, все что без примечаний - реализовано):
- Проверка целостности без размонтирования;
- Доступные для записи снимки (writeable snapshots);
- Динамическое выделение индексных дескрипторов (динамические иноды, dynamic inodes);
- Интеграция с device-mapper;
- легкое добавление/удаление/замена устройства хранения (диск целиком или раздел) на смонтированной ФС.
- Поддержка сложных многодисковых конфигураций — RAID уровней 0, 1, 5, 6 и 10 (реализовано, но 5 и 6 пока не рекомендуются к промышленному использованию), а также реализация различных политик избыточности на уровне объектов ФС — то есть возможно назначить, к примеру, зеркалирование для какого-либо каталога или файла (в планах).
- Сжатие файлов: (zlib, lzо, zstd (c v4.14) - реализовано;
- Подтома (subvolumes);
- Дефрагментация смонтированной файловой системы.
- Copy-on-write (COW) журналирование.
- Лимиты (отдельно для каждого подтома или группы подтомов, по фактически занимаемому месту или по «официальному»)
- Контроль целостности блоков данных и метаданных с помощью контрольных сумм. Можно выбрать один из 4 алгоритмов.
- Зеркалирование метаданных даже в однодисковой конфигурации (отключается на ssd).
- Поддержка разреженных файлов.
- Полностью распределенное блокирование.
- Поддержка ACL.
- Защита от потери данных.
- Поддержка NFS (пока не полная).
- Флаги совместимости, необходимые для изменения дискового формата в новых версиях btrfs с сохранением совместимости со старыми.
- Резервные копии суперблока, по крайней мере по одной на устройство.
- Гибридные пулы (в планах). btrfs старается перемещать наиболее используемые данные на самое быстрое устройство, вытесняя с него «залежавшиеся» блоки. Эта политика хорошо согласуется с появившейся недавно моделью использования SSD совместно с обычными дисками.
- Балансировка данных между устройствами в btrfs возможна сразу после добавления диска к пулу, отдельной командой, а не только постепенно, в процессе использования (как это реализовано в ZFS).
- Диски для горячей замены, поддержка которых появилась и в ZFS (в планах).
- Offline дедубликация (в примонтированном виде, но после окончания записи - ядро 3.12 и новее) В перспективе - дедубликацию можно будет включить сразу при записи файла.
- Поддержка swap-файлов (с версии 5.0, ранее можно было сделать через loop-устройство). Но есть ограничения: на swap-файле должны быть отключены COW и сжатие, файл при этом должен находится на одном устройстве (не RAID) и он не может попасть в снимок. В перспективе часть ограничений предполагается снять.
Текущий статус файловой системы btrfs
Формат представления btrfs на диске является стабильным - он зафиксирован и правки в него не вносятся (будут вноситься только в самом крайнем случае). Т.е. вы можете смело обновлять программное обеспечения для работы с btrfs и не опасаться, что данные на диске будут храниться в формате не совместимом с драйверами.
Весь код, необходимый для функционирования btrfs (драйвер файловой системы btrfs), включен в ядро Linux, и начиная с версии 4.3.1 (16.11.2015) btrfs имеет статус стабильной. Ранее, начиная с версии 2.6.29-rc, драйвера btrfs входили в состав ядра в статусе экспериментального.
Код утилит, необходимых для обслуживания и настройки btrfs, поставляется отдельным пакетом btrfs-tools. Его версии имеют нумерацию, соответствующую версии ядра Linux. Вы можете использовать более новые версии btrfs-tools, нежели установленное у вас ядро, однако использовать версию btrfs-tools меньше, чем версия установленного ядра, не рекомендуется.
Поддержка btrfs в ядре Linux
Код драйвера btrfs (включенного в ядро) активно обновляется новым функционалом. Поэтому, если вы хотите работать с самыми последними функциями, добавленными в btrfs, то используйте наиболее свежие ядра из доступных (и желательно не ниже 4.3.1).
Утилиты для работы с btrfs - btrfs-tools
Стабильная версия btrfs-tools
Стабильная версия пакета с утилитами для поддержки btrfs доступна в стандартном репозитории Ubuntu. Если вы при установке системы выберете один из разделов как раздел btrfs, то пакет btrfs-tools будет установлен во время инсталляции. В уже установленной системе (без btrfs-разделов) установить утилиты для поддержки btrfs можно, выполнив команду:
sudo apt-get install btrfs-tools
Вы можете также скачать и установить наиболее свежую нестабильную версию или более свежую стабильную версию из репозитория на launchpad Там есть и исходники, и бинарные .deb пакеты, собранные майнтейнерами Ubuntu.
Самая новейшая нестабильная версия btrfs-tools
Если вам нужны самые последние доработки в btrfs, то стоит устанавливать нестабильную версию непосредственно из репозитория, где ведется разработка btrfs-progs. Для получения последней версии btrfs-progs можно использовать следующий скрипт:
#!/bin/bash -e sudo apt-get build-dep btrfs-tools dir=$RANDOM && mkdir -p /tmp/$dir && cd /tmp/$dir git clone git://git.kernel.org/pub/scm/linux/kernel/git/mason/btrfs-progs.git ./ sudo make install
Он автоматически скачивает последнюю доступную версию, компилирует и устанавливает в систему (в обход пакетной системы, что означает отсутствие автоматических обновлений).
Исправить этот недочет просто: создайте символьную ссылку в /bin, указывающую на /sbin/fsck.btrfs:
sudo ln -s /bin/fsck.btrfs /sbin/fsck.btrfs
Использование btrfs
Как уже было сказано, поддержка btrfs уже включена в ядро Linux, и если у вас ядро v.4.3.1 или более новое, то вы можете смело использовать btrfs. В каждой новой версии ядра добавлялись и по сей день добавляются довольно значительные изменения. Поэтому, чем новее у вас ядро, тем более проработанная версия btrfs у вас будет.
Экспериментальная площадка
Вы можете смело экспериментировать с btrfs, не создавая ее на носителе: можно создать ее в файле.
# Создадим пустой файл размером 1Gb в домашнем каталоге пользователя truncate -s 1G ~/btrfs-image # Создадим в образе файловую систему btrfs mkfs.btrfs ~/btrfs-image # Смонтируем нашу экспериментальную ФС (монтирования с -o loop недостаточно, нужно настроить loop устройство вручную) losetup /dev/loop0 ~/btrfs-image mount /dev/loop0 /mnt
Вот мы и получили в /mnt площадку для экспериментов с btrfs. Можно приступать к изучению возможностей этой файловой системы.
Возможности btrfs
COW - Copy On Write
COW - Copy On Write - Копирование при записи - одна из ключевых особенностей btrfs. Суть этого механизма в том, что любая запись в существующий файл не перезаписывает его содержимое, а создает новые структуры данных, которые и будут хранить данные файла после окончания записи (просто по окончанию записи iNode файла будет ссылаться на новую структуру). Оставшиеся после записи блоки файла с данными до начала записи могут быть освобождены или, если на них продолжает ссылаться другой iNode, остаться занятыми первичной версией файла.
Если же запись по какой-то причине не завершится, то файл без каких либо дополнительных действий сохранит свое содержимое до начала записи, нужно будет только освободить те структуры, в которые не удалась запись.
При таком подходе журналирование данных файла происходит само собой. Точно так же можно поступать и с метаданными. Таким образом повышается производительность не только на запись, но и откат после неуспешной записи производится практически мгновенно.
Создать «теневую копию» данных (т.е. сделать дополнительную ссылку на те же данные на которые ссылается iNode существующего файла) можно командой:
cp --reflink <оригинальный файл> <теневая копия>
Оба файла после такой команды будут хранить свое содержимое в одном месте (почти как hard-link), но как только в оригинальный файл будут записаны новые данные - он изменится, а теневая копия - сохранит оригинальное содержимое. Фактически, такое копирование - это просто создание новой записи в каталоге файлов. Копирования данных не происходит. А значит даже очень большой файл копируется (а точнее клонируется) практически мгновенно.
Используя рекурсивное копирование (cp -r) можно создавать мгновенные копии каталогов вместе со всеми их вложениями. И такое копирование тоже будет занимать очень мало времени независимо от объема данных, хранящихся в копируемом/клонируемом каталоге. Однако может так статься, что какие-то файлы нельзя скопировать клонированием, например на файле отключен COW или файл находится в другой ФС смонтированной где-то внутри копируемого каталога. Можно указать –reflink=auto - тогда все, что нельзя скопировать клонированием будет копироваться как обычно.
Сделать теневую копию сразу целого подтома можно с использованием снимков).
COW также позволяет «размазать запись» по носителю, что полезно для SSD. Многократная перезапись файла будет на деле осуществляться каждый раз в новые блоки устройства.
Однако, у COW есть и «подводные камни». Если файл обновляется не целиком, а изменяется только часть в его середине, то эта середина уже однозначно будет хранится не в том же месте, где голова и хвост. Таким образом, такая запись разбивает файл как минимум на три фрагмента, раскиданных по разным блокам устройства. Т.е. файл стал фрагментированным, и если на ssd это не имеет особого значения, то на HDD высокая фрагментация файлов приводит к снижению производительности файловой системы. Об этом недостатке COW стоит не забывать.
Если COW начинает мешать, то его можно отключить (см раздел "Настройки"). Это приведет к тому, что содержимое файла не будет записываться каждый раз в новые блоки (запись будет производиться поверх старых данных), т.о. вместе с отключением COW, вы теряете быстрое журналирование данных.
Подтома
Внутри файловой системы btrfs можно создать несколько выделенных файловых систем - подтомов. Свободное пространство делится между всеми такими подтомами, а также могут совместно использоваться одинаковые данные (при выполнении копирования с опцией –reflink, дедубликации или при использовании снимков). При необходимости на подтома можно установить квоты (ограничить размер). Так же у подтомов могут быть настроены разные механизмы сжатия и некоторые другие свойства. Т.о. подтома btrfs - это вполне полноценная замена нескольким файловым системам, размещенным на отдельных разделах диска.
Дополнительное преимущество от использования подтомов на HDD-диске (по сравнению с разделами) заключается в том, что btrfs начинает заполнять предоставленный ей объем на диске с начала, и в одной и той же зоне располагается информация сразу всех подтомов. Т.о. головкам диска не нужно бегать по всему диску (как они бы бегали между разделами), когда нужны данные из разных разделов.
Подтома можно создавать, удалять и просматривать их список и т.п. Все возможности по работе с подтомами можно изучить по:
man btrfs-subvolume
Создается подтом командой:
btrfs subvolume create {путь по которому смонтирована btrfs}/{путь и имя создаваемого подтома}
Пример:
btrfs subvolume create /backup
Удаляется подтом командой
btrfs subvolume delete {путь по которому смонтирована btrfs}/{путь и имя удаляемого подтома}
В последнних версиях btrfs удалить подтом можно также командой rm -r или rmdir. С точки зрения файловой системы подтом и каталог различаются только методом создания (ранее различались еще удалением). Во всем остальном подтома не отличаются от каталогов. Переименовывается подтом обычной командой mv.
Если необходимо, то любой подтом (даже уже смонтированный командой mount или смонтированный внутри другого смонтированного подтома) можно смонтировать еще раз в другое место. Это кардинально отличает подтома btrfs от большинства других файловых систем (обычно файловую систему можно смонтировать только один раз).
Таким образом, подтома - чрезвычайно гибкий инструмент для управления системой хранения.
Посмотреть список подтомов можно командой:
btrfs subvolume list {путь по которому смонтирован любой из btrfs-подтомов}
Пример:
btrfs subvolume list / ID 257 gen 7414 top level 5 path @ ID 258 gen 7415 top level 5 path @home
Обратите внимание на то, что у обоих подтомов указан родительский том 5 - это корневой подтом (он есть, но не показывается в выводе btrfs subvolume list), и именно он будет смонтирован при монтировании раздела диска, если явно не указать, какой подтом нужно монтировать. При этом подтома (@ и @home) будут видны как каталоги. Пример (раздел диска /dev/sda2 содержит btrfs):
mount /dev/sda2 /mnt ls /mnt @ @home
Что бы получить в точке монтирования ФС конкретный подтом, нужно в опциях монтирования указать имя (или ID) подтома, который нужно монтировать. Пример:
mount -o subvol=@ /dev/sda2 /mnt # или -o subvolid=257 - если монтировать по ID подтома. ls /mnt bin dev initrd.img lib64 opt run sys var boot etc initrd.img.old media proc sbin tmp vmlinuz cdrom home lib mnt root srv usr vmlinuz.old
Именно так прописывает монтирование подразделов стандартный установщик в fstab. Пример строк fstab, которые обычно создает установщик:
UUID=0260463a-1468-422b-8bbb-f80e98e34001 / btrfs subvol=@ 1 1 UUID=0260463a-1468-422b-8bbb-f80e98e34001 /home btrfs subvol=@home 0 2
Для того, чтобы ядро смогло смонтировать корневую ФС, расположенную в подтоме btrfs, ядру передается указание на нужный подтом в параметре rootflags. Все нужные опции в стандартной установке Ubuntu проделывают скрипты установки и настройки менеджера загрузки GRUB. Пример того, как может выглядеть строка загрузки ядра:
vmlinuz-3.19.0-51-generic root=UUID=0260463a-1468-422b-8bbb-f80e98e34001 ro quiet rootflags=subvol=@
Когда раздел с btrfs монтируется без указания подтома, то монтируется подтом по умолчанию. Стандартно это служебный подтом (ID=5). Это поведение можно изменить, т.е. указать другой подтом как подтом по умолчанию (тот, который монтируется без указания подтома). Поменять подтом по умолчанию можно командой:
btrfs subvolume set-default {ID подраздела} {путь куда смонтирован один из подтомов BTRFS}
Для возврата к стандартной конфигурации установите корневой подтом btrfs (ID=5) как подтом по умолчанию:
btrfs subvolume set-default 5 /
Снимки
Снимок (snapshot) - это зафиксированное (в момент создания) состояние подтома, но нужно сразу оговорится, что по умолчанию снимки в btrfs - доступны для изменения. Т.е. слова «зафиксированное состояние» - не совсем подходящие.
Чуточку более «правильный снимок» можно создать если при создании снимка указать опцию -r - тогда снимок будет сделан в состоянии read-only (но если нужно, то и ему можно будет вернуть режим read/write позже).
Создается снимок командой:
btrfs subvolume snapshot [-r] <подтом с которого делается снимок> <путь и имя снимка>
В момент создания снимка создается «теневая» копия метаданных оригинального подтома (inode снимка содержит копии ссылок из inode оригинального подтома), все дальнейшие изменения, происходящие в подтоме, (а также в снимке) выполняются по алгоритму Copy On Write. Таким образом на диске все те метаданные и данные, которые в томе и снимке не изменялись хранятся в общем месте, а все новые и перезаписанные данные и метаданные хранятся в независимых, разных структурах (у оригинального подтома они свои и у снимка - свои собственные).
То, что снимки работают в режиме RW полностью размывает различие между снимком и подтомом. Снимок, представляет собой точно такую же отдельную ФС как и подтом. Фактически создание снимка - это создание тома, только в отличии от btrfs subvolume cereate, создающего пустой подтом, btrfs subvolume snapshot создает новый подтом как копию/клон ранее существовавшего.
Посмотреть какие снимки были ранее сделаны с данного подтома можно в выводе команды:
btrfs subvolume show <путь к подтому>
Пример вывода:
btrfs su sh @ /home/stc/btrfs/btrfs/@ Name: @ UUID: 92f2683e-f412-c242-90c8-07aa2a23857d Parent UUID: - Received UUID: - Creation time: 2016-09-19 11:09:51 +0300 Subvolume ID: 256 Generation: 30 Gen at creation: 11 Parent ID: 5 Top level ID: 5 Flags: - Snapshot(s): @backup @backup1
Использование снимков для создании точки отката
Снимки позволяют делать быстрые резервные копии или иными словами - точки отката. Например: вы хотите поэкспериментировать с системой или обновить ее, но не уверены, что не сломаете ее или что новая версия вас устроит. Тогда сделаете перед экспериментами/установкой снимок корневого раздела:
mount /dev/sda2 /mnt # монтируем корень btrfs (если изменили подтом по умолчанию то укажите -o subvolid=5) btrfs sub snapshot /mnt/@ /mnt/@_bak # делаем снимок корневой ФC Linux umount /mnt # размонтируем корень btrfs
После этого можете смело ломать или переустанавливать систему (без форматирования). Чтобы вернуться в первоначальное состояние грузитесь с LiveCD и делаете:
mount /dev/sda2 /mnt mv /mnt/@ /mnt/@_broken mv /mnt/@_bak /mnt/@ umount /mnt
Если вы не планируете продолжать эксперименты со сломанной/новой системой, то подтом @_broken можно удалить.
Снимки невозможно удалить как каталоги они удаляется командой для работы с подтомами:
btrfs subvolume delete /mnt/@_broken
Использование снимков для инкрементального резервного копирования
Выше было рассказано как делать резервные копии с возможностью возврата к резервной копии. Если же вам нужно иметь несколько точек отката, то можно держать для каждой точки отката свой снимок, однако такой подход имеет несколько недостатков:
- Снимок не позволяет повторно использовать то пространство, которое уже не используется в текущей версии под-тома: например файл перезаписан и, если без снимка блоки, в которых хранилась старая версия файла, освобождаются для повторного использования, то когда этот файл находится в снимке - его блоки будут продолжать быть занятыми. Таким образом имея много исторических снимков мы практически запрещаем повторное использование пространства, а кроме того, плодим большое количество копий метаданных, чем в итоге быстро расходуем свободное место в файловой системе.
- Держать резервную копию на том же носителе, что и рабочая версия данных - очень нездоровая идея. При выходе из строя устройства хранения мы теряем не только свежие данные, но и все резервные копии.
Если мы перенесем резервные копии на другой носитель, то мы решаем сразу обе озвученных выше проблемы. Перенести данные с btrfs можно командами btrfs send и receive. Причем эта команда способна эффективно переносить данные непосредственно из одной btfrs в другую btrfs (используя pipe: btrfs send … | btrfs receive …), а также может формировать файл для переноса (btrfs send … -f <file>), который в дальнейшем может быть развернут в другой btrfs (с использованием команды btrfs receive … -f <file>).
Пример резервного копирования подтома /home в другую файловую систему btrfs, которая смонтирована в /other:
btrfs subvolume snapshot -r /home /home_BACKUP # создаем read-only снимок - send требует, что бы отправляемый снимок был read-only sync # сбрасываем все из кэша на диск btrfs send /home_BACKUP | btrfs receive /other/ # передаем и получаем данные
В /other/home_BACKUP мы получили резервную копию. Снимок /home_BACKUP пока нам не нужен, но он потребуется для следующих шагов.
Если каждый раз переносить в резервную копию весь объем данных, то это будет каждый раз требовать передачи большого объема данных (даже несмотря на упаковку). Когда резервные копии хранятся на сетевом устройстве или в облаке, то передача больших объемов потребует и значительного времени и может даже стоить дополнительных денег (за трафик). Решение этой проблемы - инкрементальные резервные копии: одна копия (базовая) передается полностью, а далее передаются только те данные, которые были изменены. Для создания инкрементальных резервных копий нам и потребуется снимок /home_BACKUP - базовая копия.
Для создания инкрементальной резервной копии потребуется новый read-only снимок со свежими данными:
btrfs subvolume snapshot -r /home /home_BACKUP_new sync
Теперь нам нужно создать разность между базовым снимком (/home_BACKUP) и свежим (/home_BACKUP_new). Это может сделать сама команда btrfs send:
btrfs send -p /home_BACKUP /home_BACKUP_new | btrfs receive /other/
Здесь в параметре -p (от parent) указан базовый снимок, и send формирует для отправки только разницу между снимками. Причем, т.к. эта разница определяется по метаданным, это делается быстрее чем любыми утилитами типа rsync, особенно на больших файловых системах. Кроме того, что вычисляется разница, данные еще и сжимаются. Причем btrfs эффективно использует знания о файлах - если в файле (который является разницей между прошлым и новым состоянием) 5Mb нулей, то передается меньше 500 байт (в случае пустого файла btrfs использует трюк под названием «разреженные файлы»).
Что же происходит на противоположном конце, на стороне приемника данных? А тут, не смотря на то, что под именем home_BACKUP_new передавалась разница, в /other/home_BACKUP_new мы получим полное представление подобное тому, что осталось на стороне передатчика. Происходит это потому, что базовый снимок (home_BACKUP) есть и на стороне передатчика (там он вычитается из home_BACKUP_new), и на стороне приемника, где он «складывается» с переданной разницей.
Теперь у нас в оригинальной btrfs и на приемной стороне по два одинаковых снимка: home_BACKUP и home_BACKUP_new. Для вычисления следующего инкремента в оригинальной btrfs нам нужен только свежий снимок, а прошлый - можно удалить. Для удобства мы еще переименуем новый снимок так, что бы на следующей итерации он был у нас под именем прошлого/базового снимка:
btrfs subvolume delete /home_BACKUP mv /home_BACKUP_new /home_BACKUP
Для того, что бы на приемной стороне иметь соответствующий базовый снимок, надо переименовать home_BACKUP_new в home_BACKUP, но для начала нужно решить, что делать с предыдущим снимком home_BACKUP. Если вам нужны множество точек отката, то home_BACKUP можно переименовать с указание даты:
mv /other/home_BACKUP /other/home_BACKUP.$(date +%Y-%m-%d)
Если же вас интересует только самая последняя точка восстановления, то старый снимок можно удалить.
btrfs subvolume delete /other/home_BACKUP
Ну и наконец, переименовываем новый снимок:
mv /other/home_BACKUP_new /other/home_BACKUP</code>
Восстановление данных производится в обратном порядке. И при этом, если на стороне приемника (рабочей btrfs) есть базовый снимок, который есть и на передающей стороне, то и при восстановлении также можно передать только разницу между самым последним снимком и тем базовым, который, есть у обоих сторон.
Пример полного скрипта: для резервного копирования корня с рабочего диска (/dev/sda) на резервный (/dev/sdb), на обоих дисках btrfs находится во втором разделе:
#!/bin/bash # создаем временные точки монтирования src=$(mktemp -d "${TMPDIR:-/tmp/}$(basename 0).XXXXXXXXXXXX") dst=$(mktemp -d "${TMPDIR:-/tmp/}$(basename 0).XXXXXXXXXXXX") #монтируем корни файловых систем btrfs mount /dev/sda2 $src mount /dev/sdb2 $dst if [ -e $src/root_BCKP ] then # если первый запуск (нет базовых снимков) - создаем полный бекап # Создаем базовый снимок (в режиме readonly) btrfs subvolume snapshot -r $src/@ $src/root_BCKP sync # Отправляем базовый снимок на резервный диск btrfs send $src/root_BCKP | btrfs receive $dst/ else # Не первый запуск - делаем инкрементальный бекап # Переименовываем базовый снимок mv $src/root_BCKP $src/root_BCKP_prev mv $dst/root_BCKP $dst/root_BCKP_prev # Создаем текущие снимки btrfs subvolume snapshot -r $src/@ $src/root_BACKUP sync # Отправка инкрементального бекапа btrfs send -p $src/root_BCKP_prev $src/root_BACKUP | btrfs receive $dst/ fi # Сделано: В $dst/root_BACKUP создана полная резервная копии корня. # Размонтируем корни файловых систем umount $src umount $dst # Удаляем временные точки монтирования rmdir $src rmdir $dst
Квоты
То что подтома разделяют общее пространство всей btrfs это и плюс (не возникает ситуации когда один раздел забит под завязку, а второй полупустой), но с другой стороны, это же и минус: подтом, куда, к примеру, по ошибке начали записываться данные в бесконечном цикле, быстро исчерпает место в btrfs и его не останется ни в одном другом подразделе. В случае подобных рисков полезно ограничивать то пространство, которое может использовать подтом. Т.е. в нашем примере, если бесконечная запись идет в раздел, место на котором ограниченное лимитом, то задача вызвавшая бесконечную запись получит ошибку как только кончится выделенный лимит (а не тогда когда кончится место во всей ФС).
В btrfs, начиная с версии ядра 3.11 поддерживается управление квотами подтомов. По умолчанию, при создании btrfs квоты не включены. Для того, что бы включить поддержку квот нужно выполнить:
btrfs quota enable {точка монтирования btrfs}
При этом более новые версии btrfs автоматически создают ресурсные подгруппы (qgroup) на все подтома. Посмотреть ресурсные группы можно командой
btrfs qgroup show {точка монтирования btrfs}
Если ваша версия btrfs не создала ресурсные группы, то их придется создать вручную и запустить пересканирование
btrfs subvolume show {точка монтирования btrfs} | cut -d' ' -f2 | xargs -I{} -n1 btrfs qgroup create 0/{} {точка монтирования btrfs}
btrfs quota rescan {точка монтирования btrfs}
Как вы поняли из команд выше создается ресурсная группа командой
btrfs qgroup create {уровень/ID} {точка монтирования btrfs}
Для наименования ресурсных групп предусмотрена нотация <уровень>/<ID>. Уровень 0 зарезервирован для групп связанных с подтомами ID которых указан во второй части. Именно такие группы автоматически создает btrfs при quote enable и при создании нового подтома (при включенных квотах).
Но группы могут быть привязаны и не к одному подтому, а к группе подтомов. Для ассоциации группы с несколькими подтомами используется команда assign
brtfs qgroup assign {привязываемая группа} {группа в которую осуществляется привязка} {точка монтирования btrfs}
qgroupid rfer excl -------- ---- ---- 0/5 16.00KiB 16.00KiB 0/261 3.91GiB 3.91GiB 0/262 42.37GiB 42.37GiB 0/311 3.91GiB 16.00KiB 1/0 46.27GiB 46.27GiB
Здесь мы видим объемы занятые корневым подтомом btrfs (ID=5), и еще двумя подтомами (с ID 261 - корневая FS системы и 262 - /home), снимком корня (ID=311), а также вы видите ресурсную группу 1/0 которую я создал вручную и ассоциировал с ней группы 0/5, 0/261 и 0/262.
Две колонки показывают занятое в каждой группе место. Но если refr показывает место занятое «официально» (то что вы могли бы получить через команду du запущенной внутри подтома), то колонка excl показывает «черную бухгалтерию» btrfs. Как вы видите, ресурсная группа снимка официально занимает 3.91GiB, а фактически на диске занимает только 16.00KiB. т.е. фактически, не смотря на то, что снимок содержит полную копию корневой файловой системы, в снимке хранится только незначительный набор метаданных, а почти все данные используются одновременно и корнем и снимком. Т.е. все то уникальное (эксклюзивное), что есть у снимка - помещается в 16.KB.
Группа 1/0, созданная вручную позволяет контролировать объем занимаемый всем подтомами с реальными данными.
Ну, а теперь собственно основное, ради чего создаются ресурсные группы - лимиты. Лимит на группу устанавливается командой
btrfs qgroup limit [-c] [-e] <размер>|none {группа} {точка монтирования btrfs}
Лимит может относится к файлам после сжатия - опция -с1), а так же можно ограничить эксклюзивное место занимаемое группой - опция -e. Без опции -e, указанный лимит относится к «официальному» объему.
Свойства
Команда:
btrfs property get {путь куда смонтирован подтом}
Показывает свойства установленные для подтома или каталога, а команда:
btrfs property set {путь куда смонтирован подтом} {имя свойства} {значение}
Устанавливает свойство в указанное значение. Свойств пока всего 3:
- ro - флаг read-only, значения true или false
- label - метка тома, значение - строка символов или пустая строка, когда метку нужно сбросить.
- compression - сжатие подтома или каталога, значения lzo, zlib или пустая строка, когда сжатие нужно отключить.
- ro может относится только к подтому (попытка установить это свойство на каталог подтома приведет к ошибке). Действует ro на весь подтом в целом.
- label может устанавливаться и относится только к файловой систем btrfs в целом - т.е. корневому подтому или подтому по умолчанию.
- compression можно установить как на подтом (включая корневой с ID=5) так и на отдельный каталог подтома или даже на отдельный файл. Действует compression только на тот объект на котором стоит, но установленный на каталог compression будут унаследован всеми новыми вложенными файлами и каталогами. Если установить compression на каталог, в котором уже есть другие файлы/каталоги, то они не получат свойство compression автоматически. Более подробно вопросы сжатия будут рассмотрены в разделе «Упаковка данных».
Настройки
btrfstune - приложение для тонкой настройки (тюнинга) системных параметров FS.
usage: btrfstune [options] device
-S value Включить/Выключить RO режим
-r Включить расширенные inode refs #3.11 ядро и старше
# -r чтобы увеличить максимальное количество жёстких ссылок на FS
-x Включить тощие экстенты в метаданных #3.11 ядро и старше
# -x уменьшает размер метаданных на 30%.
Более полно тут (англ.)
Настройки нужно применять непосредственно к разделу на котором стоит btrfs, и раздел этот не должен быть смонтирован в момент выполнения этой команды.
Отключение COW
Большие файлы, которые постоянно изменяются, например виртуальные диски VirtualBox или файлы скачиваемые через torrent, особо подвержены фрагментации. Для таких файлов рекомендуется отключить copy-on-write.
Отключить можно только для пустых файлов. Если отключить для директории, то этот атрибут унаследуется только вновь создаваемыми файлами. Для отключения copy-on-write для новых виртуальных машин выполните команду
chattr +C ~/VirtualBox\ VMs/
Посмотреть наличие атрибута можно командой
lsattr file_name
chattr/lsattr позволяют задать и другие свойства файлов. Описание всех возможных атрибутов можно посмотреть в man chattr.
Сжатие/упаковка данных
btrfs поддерживает автоматическую упаковку данных при записи и распаковку при чтении. Поддерживаются три алгоритма сжатия:
- zlib - достаточно эффективное сжатие в 2,7-3 раза, но довольно медленные и упаковка/распаковка
- lzo - быстрая упаковка/распаковка, но не слишком эффективное сжатие примерно - в 2 раза или меньше
- zstd (с v4.14) - настраиваемый вариант сжатия - можно задать разные уровни компрессии (zlib примерно аналогичен zstd:3).
В апдейте добавляющем zstd есть оценочная таблица с характеристиками разных методов сжатия:
| Метод | сжатие| Скорость сжатия MB/s | Скорость разжатия | |---------|-------|----------------------|---------------------| | None | 0.99 | 504 | 686 | | lzo | 1.66 | 398 | 442 | | zlib | 2.58 | 65 | 241 | | zstd:1 | 2.57 | 260 | 383 | | zstd:3 | 2.71 | 174 | 408 | | zstd:6 | 2.87 | 70 | 398 | | zstd:9 | 2.92 | 43 | 406 | | zstd:12 | 2.93 | 21 | 408 | | zstd:15 | 3.01 | 11 | 354 |
Текущее состояние файла (упакован и как) определяется параметрами в i-node, а вот упаковывать ли вновь записываемыми денные определяется опциями монтирования и свойством сжатия задаваемом на каталогах и файлах (все опции монтирования см. тут или параметры монтирования агл.(более полно)). Вновь записываемые данные сжимаются:
- всегда: если файловая система смонтирована с -o compress-force
- никогда: если флаг NOCOMPRESS установлен на файле/каталоге (chattr -c)
- если возможно: если флаг COMPRESS установлен (chattr +c) на файле или унаследовал его от каталога при создании нового файла.
- если возможно: если файловая система смонтирована c -o compress
Отдельно стоит уточнить, что означает «если возможно»: дело в том, что btrfs не станет упаковывать файл, если начав его упаковку обнаружит что выигрыша от упаковки нет. Так к примеру практически никогда не упаковываются JPEG-файлы - сам формат JPEG подразумевает достаточно эффективную упаковку данных внутри файла. Однако монтирование с -o compress-force будет заставлять упаковывать даже JPEG-файлы (скорее всего с 0-вым эффектом, но с затратами процессорного времени на упаковку\распаковку).
Учтите что монтирование с опцией compress не устанавливает атрибут +c файла.
btrfs fi defrag -rc {путь куда смонтирован подтом btrfs} # упаковка всех файлов на ФС
Распаковка файлов с помощью команды defrag на данный момент невозможна.
каталога compression Свойство файла/каталога compression это аналог атрибута 'с' (из числа расширенных атрибутов файлов, управлять которыми можно через chattr/lsattr).
chattr -R -c * # сникаталога compressionмает свойство compression со всех файлов рекурсивно, начиная с текущего каталога.
А вот установка свойства compression через расширенный атрибут 'c' позволяет установить только компрессию по умолчанию (zlib). Если хотите установить другой тип компрессии, то пользуйтесь командой btrfs property set <файл> compression «<тип сжатия>«.
Информация о файловой системе
Системная утилита df не может корректно показать данные об использованном пространстве на btrfs. Собственно, особенности хранения данных в btrfs (совместное использование данных в подтомах и снимках, а также дедупликация данных) вообще делают невозможным однозначно определить, какое место на диске занимают данные того или иного отдельно взятого подтома/снимка.
Вопрос о доступном свободном месте - тоже не имеет однозначного ответа для btrfs: тут и сжатие, и совместное использование данных, и некоторые другие нюансы просто не позволяют точно сказать сколько свободного места осталось в файловой системе btrfs.
Btrfs предоставляет несколько команд для просмотра информации по использованию дискового пространства и состоянию файловой системы. Это команды:
btrfs filesystem df {путь, куда смонтирован подтом btrfs} # обобщенная информация о файловой системе
btrfs filesystem show {путь, куда смонтирован подтом btrfs} # обобщенная информация об использовании дисков файловой системой
btrfs filesystem usage {путь, куда смонтирован подтом btrfs} # детальная информация о статусе и состоянии файловой системы
btrfs device usage {путь, куда смонтирован подтом btrfs} # детальная информация о распределении данных файловой системы по дискам
btrfs device stats {путь, куда смонтирован подтом btrfs} # статистика ошибок/сбоев устройств хранения
Он хоть и несколько необычный, но дает одни из самых точных данных.
btrfs filesystem df
Отображается не состояние папки, а состояние примонтированного тома, содержащего указанную папку. Если написать путь к разделу диска (например, /dev/sda2), команда не сработает: сначала нужно его примонтировать. Пример:
btrfs filesystem df /home Data, single: total=272.64GB, used=146.61GB System, DUP: total=32.00MB, used=28.00KB Metadata, DUP: total=136.00GB, used=71.46GB GlobalReserve, single: total=16.00MiB, used=0.00B
Здесь Data - информация о хранении данных, Metadata - это данные, которые содержат информацию о хранения файлов и каталогов, System - это информация о самой ФС - суперблок. О режимах single/DUP мы расскажем позже.
Тут важно отметить, что total - это не максимально возможный объем, а всего-лишь объем, который размечен в данный момент, часть дискового пространства, отведенного под btrfs, может оставаться не размеченной.
Отдельно нужно уточнить про GlobalReserve: согласно официальной Wiki, это резерв для работы ФС. Он используется при полностью занятом пространстве в ФС для служебных нужд ФС. Это значит, что даже тогда, когда ни простой пользователь, ни root ничего на файловую систему записать не могут, различные манипуляции с файловой системой все еще будут доступны. Например, можно создать снимок или удалить под-том (для удаления тоже нужно дополнительное место для метаданных, т.к. оно тоже делается с использованием механизма COW).
Таким образом, заполненная на 100% файловая система btrfs - не приводит к краху системы с крайне тяжелыми последствиями, как это свойственно многим другим ФС. Такая файловая система спокойно монтируется и там легко можно удалять файлы благодаря глобальному резерву.
btrfs filesytem show
Команда показывает агрегированное представление о используемых объемах на устройствах хранения (в примере - «забитый под завязку» данными RAID1 из трех разных по объему устройств, о том, как это делается - будет рассказано чуть позже):
btrfs f sh /mnt # "f sh" допустимое сокращение от "filesytem show"
Label: none uuid: 8e1f7f2b-f583-4ba5-8847-17feaa0fed0b
Total devices 3 FS bytes used 1.79GiB
devid 1 size 1.00GiB used 1023.00MiB path /dev/loop0
devid 2 size 1.00GiB used 1023.00MiB path /dev/loop1
devid 3 size 2.00GiB used 2.00GiB path /dev/loop2
Тут в Total показано число устройств хранения и сколько на них в целом занято файлами, хранимыми в файловой системе (только data, без meta и system). Ниже - детальная информация по каждому устройству отдельно. Тут size - это как раз максимально возможный объем на данном устройстве, а used - размеченное на устройстве место.
btrfs filesystem usage
Пример вывода (это тестовая файловая система btrfs на основе 2-х файловых образов, собранных в raid1):
btrfs f u /mnt # "f u" - допустимое сокращение от "filesystem usage" Overall: Device size: 4.00GiB Device allocated: 1.38GiB Device unallocated: 2.62GiB Device missing: 0.00B Used: 560.00KiB Free (estimated): 1.72GiB (min: 1.72GiB) Data ratio: 2.00 Metadata ratio: 2.00 Global reserve: 16.00MiB (used: 0.00B) Data,RAID1: Size:416.00MiB, Used:136.00KiB /dev/loop0 416.00MiB /dev/loop2 416.00MiB Metadata,RAID1: Size:256.00MiB, Used:128.00KiB /dev/loop0 256.00MiB /dev/loop2 256.00MiB System,RAID1: Size:32.00MiB, Used:16.00KiB /dev/loop0 32.00MiB /dev/loop2 32.00MiB Unallocated: /dev/loop0 1.31GiB /dev/loop2 1.31GiB
В выводе представлено детальное состояние файловой системы, общие используемые и доступные объемы, детали размещения системных данных, метаданных и данных файлов. Кроме того, показано и то, на каких устройствах хранения и как организовано хранение различных данных и сколько занято места. Тут Size - размеченное место, а Used - использованное. В самой последней секции показан объем неразмеченного пространства на устройствах хранения.
btrfs device usage
Пример вывода (RAID1 на 3 «дисках» разного размера):
btrfs d us /mnt # "d us" - допустимые сокращения от "device usage" /dev/loop0, ID: 1 Device size: 1.00GiB Data,RAID1: 416.00MiB Metadata,RAID1: 204.75MiB Unallocated: 403.25MiB /dev/loop1, ID: 2 Device size: 1.00GiB Data,RAID1: 318.50MiB System,RAID1: 8.00MiB Unallocated: 697.50MiB /dev/loop2, ID: 3 Device size: 2.00GiB Data,RAID1: 734.50MiB Metadata,RAID1: 204.75MiB System,RAID1: 8.00MiB Unallocated: 1.07GiB
Здесь показана вместимость, сколько и чем занято, и сколько еще осталось свободного места на каждом устройстве.
btrfs device stats
btrfs d st /mnt # "d st" - допустимое сокращение от "device status" [/dev/loop0].write_io_errs 0 [/dev/loop0].read_io_errs 0 [/dev/loop0].flush_io_errs 0 [/dev/loop0].corruption_errs 0 [/dev/loop0].generation_errs 0 [/dev/loop1].write_io_errs 0 [/dev/loop1].read_io_errs 0 [/dev/loop1].flush_io_errs 0 [/dev/loop1].corruption_errs 0 [/dev/loop1].generation_errs 0
Эта команда показывает статистику ошибок и сбоев в работе каждого устройства (в примере их два).
Утилита btrfs имеет в своем составе скрипты авто-дополнения и вы можете набрав 1-2 буквы и нажав tab дополнять команды при наборе, однако если 1-2 буквы уникально идентифицируют команды, то их можно и не дополнять. Утилита прекрасно все дополняет сама внутри себя.
Изменение размера btrfs
btrfs поддерживает изменение размеров (увеличение и уменьшение) при смонтированной ФС. Само собой, для увеличения ФС нужно, чтобы содержащий ФС раздел был больше, чем размер ФС, а для уменьшения - в ФС должно быть достаточно свободного пространства для уменьшения.
Изменяется размер ФС командой:
btrfs filesystem resize {+/-размер или просто размер} {путь, куда смонтирован любой подтом btrfs}
Например указанный размер +2g увеличит ФС на 2 гигабайта, -1g - уменьшит на 1 гигабайт, а 40g - установит полный размер ФС в 40 гигабайт.
Контрольные суммы
btrfs использует для контроля целостности данных контрольные суммы. Они в частности позволяют восстанавливать целостность данных на RAID массивах в случае, когда с одним из устройств временно пропадает связь (и при этом массив продолжает использоваться дальше в режиме degraded).
Поддерживаются алгоритм CRC32C по умолчанию и 3 дополнительных алгоритма (с версии ядра 5.5).
CRC32C (32-бит) - По умолчанию, лучший в плане совместимости, очень быстрый (современные процессоры поддерживают его на уровне инструкций), не устойчивый к коллизиям, но вполне приличный уровень определения ошибок.
XXHASH (64-бит) - хорошая замена CRC32C, очень быстрый (оптимизирован для использования инструкций современных процессоров), хорошая устойчивость к коллизиям и хороший уровень определения ошибок.
SHA256 (256-бит) - криптографически устойчивый хэш, довольно медленный, но может быть ускорен аппаратными ускорителями, сертифицирован FIPS и довольно широко используется.
BLAKE2b (256-бит) - криптографически устойчивый хэш, довольно быстрый при использовании SIMD расширений команд процессоров, не стандартизован, но основан на BLAKE - одном из финалистов конкурса SHA3, широко используется, алгоритм - часть BLAKE2b-256, который оптимизирован для 64-битных платформ.
Размер хэша влияет на размер части блока данных хранящего контрольную сумму. Блок метаданных имеет фиксированный объем до 256 бит (32 байта), таким образом тут не возникает увеличения. Каждый блок данных имеет индивидуальную контрольную сумму, сохраняющуюся вместе с данными для организации b-tree листа.
Сравнительные производительности алгоритмов, в сравнении с CRC32C на платформе Intel 3.5GHz:
Digest Cycles/4KiB Ratio CRC32C 1700 1.00 XXHASH 2500 1.44 SHA256 105000 61 BLAKE2b 22000 13
Проверка/пересчет контрольных сумм - длительная и потому фоновая операция (если не указать явно выполнять интерактивно). Поэтому отдельно можно запустить пересчёт (команда start), остановить (cancel) и посмотреть статус (status). Пример команды запуска:
btrfs scrub start -Bd /home # -B Не запускаться в фоновом процессе (интерактивное исполнение) # -d Выводить результаты (только при -B)
Все опции команды btrfs scrub можно посмотреть в
man btrfs-scrub
Балансировка
При балансировке на btrfs пере-создаются метаданные и пере-распределяются данные файлов. Запускается балансировка командой:
btrfs balance start /home
Балансировка может потребовать перемещения большого объема данных, это потребует значительного времени на выполнение, поэтому команда start запускает балансировку в фоновом режиме. Для управления процессом балансировки служат команды:
btrfs balance status <path> # показывает статус текущего процесса балансировки (активного или приостановленного) btrfs balance pause <path> # приостанавливает текущий процесс балансировки btrfs balance cancel <path> # прекращает текущий процесс балансировки btrfs balance resume <path> # возобновляет текущий процесс балансировки, который ранее был поставлен на паузу
Команда балансировки может использоваться не только для оптимизации метаданных, она позволяет изменять тип хранения данных. Делается это с помощью фильтра convert, который может применяться раздельно для данных, метаданных и/или системных данных.
Фильтры балансировки
Фильтры - это специальные параметры, позволяющие управлять балансировкой, все фильтры применяются к 3-м типам данных: System (мастер-запись), Metadata (i-node и каталоги), Data (собственно данные файлов). Фильтры выглядят следующим образом:
- s<filter>=<params> #фильтр для операций с системными данными, требует параметра –force
- m<filter>=<params> #фильтр для операций над метаданными
- d<filter>=<params> #фильтр для операций над данными
Фильтр и параметры:
convert - фильтр служит для изменения типа хранения данных, в качестве параметров принимает следующие значения: single, dup, raid0, raid1, raid10, raid5 и raid6.
soft - «мягкий» параметр, фактически нужен только при изменении типа хранения данных (для фильтра convert), позволяет производить балансировку только минимально необходимого числа данных, а не всего, что есть на диске.
Пример команды, конвертирующей тип хранения данных:
btrfs balance start -dconvert=raid1,soft -mconvert=raid1,soft -sconvert=raid1,soft --force /mnt
Обо всех возможностях команды btrfs balance можно узнать в
man btrfs-balance
Btrfs на нескольких устройствах
Btrfs поддерживает встроенную систему управления устройствами хранения. При этом устройства могут выстраиваться в разных конфигурациях. Поддерживаются следующие режимы работы: single, dup, raid0, raid1, raid10, raid5, raid6.
Про варианты raid* можно узнать подробнее на http://ru.wikipedia.org/wiki/RAID.
Некоторые полезные вещи можно посмотреть на вики btrfs https://btrfs.wiki.kernel.org/index.php/Using_Btrfs_with_Multiple_Devices (англ.).
Обратите внимание: btrfs не требует обязательной разметки диска на разделы, можно использовать и диски целиком, и разделы с размеченных на разделы дисков, и даже микс из разделов и дисков целиком. Для простоты в дальнейшем будем называть и разделы, и отдельные диски «устройствами».
Режим SINGLE
Когда вы создаете btrfs на одном устройстве, то все данные пишутся в режиме single, а метаданные в режиме dup (на SSD метаданные работают в режиме single). Если позже вам не будет хватать места в этой ФС, то можно просто добавить другое устройство (например, это /dev/sdb1):
btrfs device add /dev/sdb {место куда смонтирована btrfs}
После этого у вас в btrfs появится столько свободного места, сколько было на новом устройстве (на самом деле чуточку меньше, т.к. на новом устройстве сразу будет создана копия суперблока файловой системы). При этом новое устройство не обязано быть такого же размера, как и оригинальное. После добавления нового устройства вы можете монтировать btrfs с любого из устройств, на котором расположена файловая система (это позволяет сделать та самая копия суперблока на каждом устройстве). Если после добавления нового устройства выполнить балансировку, то часть данных и метаданных будет перенесена на новое устройство. Но все данные и метаданные будут продолжать работать в том режиме, в котором они хранились на первом диске (data - single, metadata - dup на HDD или single на SSD).
Это замечание также относится и к массиву RAID0.
Поэтому не забывайте о резервном копировании.
metadata - RAID1
system - RAID1
data - RAID0 !!! - почему тут RAID0, а не RAID1 (как все остальное) - это большая загадка…
Режим DUP
DUP - это дублирование данных в файловой системе (обычно только для метаданных). С версии btrfs-progs 4.5 допустимо использовать DUP и для данных. Однако, если при конвертировании способа хранения (балансировка с фильтрами) избыточность метаданных меньше, чем данных (например, метаданные в single, a данные в dup), то утилита будет ругаться. Обойти эту ругань утилиты можно опцией –force.
Про DUP важно понимать, что он не отслеживает, где именно хранятся копии, т.е. если у вас файловая система работает на двух устройствах, то DUP не гарантирует, что копии будут храниться на разных устройствах. Поэтому обычно сфера использования этого режима - дублирование метаданных в одно-дисковой конфигурации на обычных жестких дисках (на ssd метаданные - в режиме single для сокращения числа записей на носитель).
Режимы RAID
В btrfs встроена поддержка RAID 0, 1, 10, 5, 6. В RAID5/6 - пока есть еще некоторые нерешенные проблемы и их не рекомендуется использовать в промышленной эксплуатации. RAID0/1/10 - серьезных проблем не имеют и работают стабильно.
Если у вас корень на btrfs, то ядру можно передать перечень разделов RAID через ключ –rootflags, например:
rootflags=device=/dev/sdb,/dev/sdc,/dev/sdd
Тот же перечень разделов нужно записать в /etc/fstab:
device=/dev/sdb,/dev/sdc,/dev/sdd
После такого fix-а утилиты btrfs будут добавлены в initramfs стандартными средствами.
Создание btrfs на нескольких дисках
При создании btrfs на нескольких устройствах типы хранения данных и метаданных (ну или хотя бы только данных) стоит задавать вручную (иначе вы можете получить не совсем ожидаемые результаты). Выбрать тип хранения для системных данных лучше доверить драйверу.
# Создать сборку из устройств (JBOD) - заполнение данными и метаданными обоих дисков без дублирования mkfs.btrfs -m single -d single /dev/sdb /dev/sdc # Создать RAID0 - равномерное распределение данных и метаданных с чередованием записи/чтения между двумя дисками mkfs.btrfs -m raid0 -d raid0 /dev/sdb /dev/sdc # Использовать RAID1 (зеркало) и для данных и метаданных mkfs.btrfs -m raid1 -d raid1 /dev/sdb /dev/sdc # Использовать RAID10 и для данных и метаданных mkfs.btrfs -m raid10 -d raid10 /dev/sdb /dev/sdc /dev/sdd /dev/sde
Особенности много-дисковых конфигураций btrfs
Важно понимать, что то, что в btrfs названо RAID массивами - это всего-лишь подобные RAID массивам решения. Реализация RAID решений базируется исключительно на низкоуровневых структурах btrfs. Но, несмотря на то, что структуры RAID эмулируются, решения btrfs дают те же уровни доступности и производительности, которые дают классические RAID массивы.
Устройства могут быть разного размера не только для single и dup режимов, но и для RAID конфигураций. И т.к. для RAID конфигураций имеет значение только выделение отдельных кусочков (chunk-ов) в нужном количестве на нужном количестве разных устройств, то оказывается, что можно использовать гораздо больше места, чем в классических RAID (где на всех устройствах используется не больше места, чем доступно на самом маленьком устройстве).
Рассмотрим этот эффект на примере RAID1. В классическом RAID1 данные копируются на столько устройств, сколько включено в массив (собрали raid1 на 3-х дисках 1 GB и получили массив вместимостью 1 GB с тройным резервированием данных). RAID1 в btrfs реализует иную концепцию: гарантируется, что данные будут храниться в двух копиях обязательно на разных устройствах (в отличие от режима DUP). А на 3-х и более дисках обеспечить хранение 2-х копий отдельных фрагментов данных на 2-х разных устройствах можно разными способами. Для примера, если в RAID1 объединены устройства 1Тб, 1Тб и 2Тб, то на 2Тб будет одна копия всех данных, а вторые копии будут распределены между двумя 1Тб устройствами (общий доступный объем на таком массиве будет ~2Тб). В более сложных случаях (больше устройств или все три устройства - разного размера) btrfs будет использовать еще более сложные схемы распределения копий по дискам, но соблюдение правила «2 копии на 2-х разных дисках» обеспечит сохранность данных при выходе из строя любого (одного) устройства. RAID10 также может занимать больше пространства на устройствах разного размера, если этих устройств больше, чем 4.
Вы можете поиграться с размерами дисков и разными RAID конфигурациями в on-line калькуляторе и посмотреть, сколько всего будет места под файлы при разных объемах дисков, а также, какое место и на каких дисках не сможет быть использовано.
Все возможные конфигурации btrfs описаны в таблице:
| Конфигу- | Избыточность | Min-Max число | ||
|---|---|---|---|---|
| рация | Копий | Контрольные суммы | Чередование | устройств |
| single | 1 | 1-любое | ||
| dup | 23) | 1-любое4) | ||
| raid0 | 1 | 1 на N | 2-любое | |
| raid1 | 2 | 2-любое 5) | ||
| raid10 | 2 | 1 на N | 4-любое 6) | |
| raid5 | 1 | 1 | 2 на N-1 | 2-любое |
| raid6 | 1 | 2 | 2 на N-2 | 3-любое |
Имейте в виду, для метаданных уровень сохранности должен быть не ниже, чем для данных. Т.е. выбрать raid1 для хранения данных, а для метаданных оставить single - крайне неразумное решение, данные то сохранятся полностью при сбое одного из устройств хранения, но только доступа к ним не будет из-за отсутствия части метаданных. Так для двух дисков с данными в single/dup/raid0 метаданные лучше хранить в RAID1 (так при сбое одного из устройств хоть какие-то данные удастся спасти).
Варианты восстановления много-дисковых конфигураций btrfs
Если вышло из строя одно из устройств в много-дисковой конфигурации, то возможность полного восстановления данных существует только в том случае, если у вас данные хранятся в одном из следующих режимов: RAID1, RAID10, RAID5, RAID6). Если у вас данные хранились в одном из следующих режимов: single, dup, RAID0, то с частью данных вы уже сразу можете распрощаться - в такой ситуации спасти удастся только некоторые файлы (что чаще - гораздо лучше, чем вовсе ничего).
Для работы в режиме отсутствующих дисков существует опция монтирования degraded, но если диски RAID1, RAID10, RAID5, RAID6 монтируются с этой опцией в режиме RW, то single, dup, RAID0 монтируются только в режиме RO. Это не позволяет восстановить систему хранения добавлением нового устройства - но зато, когда устройства являются сетевыми и сбой был вызван недоступностью ресурса, то позже, когда доступ будет восстановлен, вы сможете легко полностью восстановить btrfs с режимами хранения single/dup/RAID0. В конфигурациях RAID1/RAID10/RAID5/RAID6 тоже возможно восстановление нормального режима, даже если была запись на файловую систему в деградированном режиме, до момента устранения проблем с потерянным устройством. Для этого потребуется выполнить перерасчет контрольных сумм и балансировку.
Btrfs c режимами хранения RAID1/RAID10/RAID5/RAID6 монтируется с опцией degraded, и на такой файловой системе можно продолжать работать (осознавая риски, конечно). И если шансов на восстановление доступа к утерянному устройству нет, но есть новое устройство, то его можно будет добавить к файловой системе и восстановить штатный режим работы много-дисковой btrfs (ускорить восстановление можно, выполнив балансировку).
Рассмотрим, как заменять утерянное устройство новым:
Для этого используется команда btrfs replace. Эта команда запускается асинхронно, поэтому первым аргументом сообщается команда: start - для запуска, cancel - для остановки и status - для того, чтобы узнать состояние. Рассмотрим формат команды запуска:
btrfs replace start <удаляемое устройство или его ID> <добавляемое устройство> <путь, куда смонтирована btrfs>
Как правило, эта команда успешно справляется со своей задачей, но есть и обходной путь (он пригодится тем, у кого более старые версии btrfs, где нет команды btrfs replace):
1. добавить новое устройство (btrfs device add),
2. удалить «умершее» устройство (btrfs device delete),
3. запустить балансировку (btrfs balance start).
Если же вы не имеете устройства на замену вышедшего из строя и решили отказаться от RAID1 и перевести данные в single, то просто удалить устройство не получится. Сначала вы должны конвертировать тип хранения выполнив балансировку:
btrfs balance start -dconvert=single,soft -mconvert=single,soft -sconvert=single,soft --force <путь куда смонтирована btrfs>
а уже после этого можно удалять вышедшее из строя устройство:
btrfs device delete missing <путь куда смонтирована btrfs>
missing - специальное значение, которое можно указать для устройств, которые уже просто отключены или недоступны (для них просто сложно указать путь).
Дефрагментация
Usage: btrfs filesystem defrag [опции] {путь, куда смонтирован подтом btrfs}
-v выводит ход выполнения (не работает в более старых версиях)
-c[lzo,zlib] сжимать файлы во время дефрагментации: пример использования -сlzo
-f записать данные сразу, не дожидаясь окончания таймера commit в 30 сек
-s start дефрагментировать дальше определённого байта в файле
-l len дефрагментировать до определённого байта в файле
-t size минимальный размер файла для дефрагментации
-r рекурсивно дефрагментировать файлы
Пример использования (рекурсивная дефрагментация всех файлов в корневой ФС с упаковкой и выводом дополнительной информации)
sudo btrfs fi def -clzo -v -r /
Текущая версия дефрагментатора не позволяет получить статистику по фрагментированности раздела. Поэтому, если вы хотите узнать, насколько фрагментировались ваши файлы, можно воспользоваться этой утилитой.
Файловая дедубликация
Дедубликация, позволяет экономить пространство на файловой системе, путём удаления повторяющихся файлов или блоков данных. На данный момент (07.12.2013), в ядре 3.12 поддерживается оффлайн дедубликация на уровне блоков, но утилиты для этого не имеется. На уровне файлов, существует утилита bedup, установка которой и использование будет описана ниже, для её использования рекомендуется последнее стабильное ядро, минимально необходимое для безопасной работы это 3.9.4. Данный скрипт устанавливает bedup-syscall, я не до конца понимаю что она даёт, но работает только под 3.12. Для успешной компиляции лучше иметь репозитории посвежее (т.е. перед компиляцией изменить имя релиза в sources.list на самый последний девелоперский и произвести sudo apt-get update, после этого скомпилировать и вернуть на место). Первое что необходимо, это её установить и скомпилировать, создайте в любом удобном месте файл установочного скрипта, например:
touch ~/bedup_install.sh
Затем скопируйте в него следующий код
#!/bin/bash -e sudo apt-get -y build-dep btrfs-tools sudo apt-get install -y python-pip python-dev libffi-dev build-essential git sudo pip install --upgrade cffi dir=/tmp/$RANDOM mkdir -p $dir cd $dir wget https://codeload.github.com/g2p/bedup/zip/wip/dedup-syscall unzip dedup-syscall -d ./ cd ./bedup-wip-dedup-syscall/ wget https://codeload.github.com/markfasheh/duperemove/zip/4b2d8b74618cc7d56c302adb8116b42bc6a3c53a unzip 4b2d8b74618cc7d56c302adb8116b42bc6a3c53a -d ./ rsync -av --progress duperemove-4b2d8b74618cc7d56c302adb8116b42bc6a3c53a/ duperemove/ git clone git://git.kernel.org/pub/scm/linux/kernel/git/mason/btrfs-progs.git ./btrfs/ sudo python setup.py install sudo rm -Rf $dir exit 0
затем необходимо сделать его исполняемым и запустить:
сhmod +x ~/bedup_install.sh && ~/bedup_install.sh
После окончания операции, для начала дедубликации всех btrfs файловых систем, подключённых к системе:
sudo bedup dedup
Установка системы на btrfs
Рекомендации по установке системы на btrfs
В случае установки системы на btrfs вам не обязательно создавать отдельный раздел под /home - можно использовать подтома. Собственно, установщик ubuntu именно так и поступит - под корень и под /home будут автоматически созданы подтома.
Однако, если вы решили, что вам нужен swap и версия вашего ядра ниже чем 5.0, то его все-таки лучше разместить на отдельном разделе, т.к. размещение swаp в файле на btrfs (до 5.0) хотя и возможно (только «обходным путем» - далее мы расскажем, как), но не рекомендуется.
Установка на сжатую fs
Установщик Ubuntu не позволяет (пока) выбрать все опции ФС, и в частности указать, что на btrfs-разделе нужно использовать сжатие. Можно поставить систему на btrfs-раздел без сжатия и включить его после установки (указав нужные ключи монтирования). Но в этом случае сжиматься будут только новые и изменяемые файлы.
Сжать записанные ранее файлы поможет дефрагментация с ключом -с<тип сжатия>. При этом дефрагментацию можно выполнить только на смонтированном подтоме, и даже с открытыми на нём файлами (например, с корнем, с которого загружена сама ОС), дефрагментатор не уплотнит те файлы, которые открыты в данный момент, и выдаст предупреждение об этом.
Но можно сразу поставить систему на том с компрессией, это можно сделать 2-мя способами.
Способ с предварительным созданием ФС вручную
Пред началом установки нужно самостоятельно разметить диск и создать файловую систему btrfs и установить у корневого подтома атрибут compression.
Подготовить файловую систему для установки (в примере ФС создается на /dev/sda2, компрессия - lzo) можно следующими командами:
mkfs.btrfs /dev/sda2 # Создаем файловую систему на разделе mount /dev/sda2 /mnt # Монтируем корневой подтом btrfs property set /mnt compression lzo # Устанавливаем компрессию umount /mnt # Демонтируем файловую систему
После этого нужно установить систему на эту файловую систему без форматирования. Выносить /home в отдельный раздел не надо (установщик сам создаст отдельные подтома для корня - @ и для домашнего каталога - @home).
После установки добавлять в fstab опции монтирования со сжатием в данном случае не обязательно: свойство сжатия уже унаследовано всеми теми подтомами и каталогами и файлами, которые были созданы при установке. Все новые файлы и каталоги, созданные после установки, также унаследуют свойство сжатия (ведь они будут созданы в каталогах, на которых это свойство уже стоит).
Способ с подменой mount
Загружаемся с LiveCD/USB, открываем терминал и выполняем:
sudo -s
Код ниже скопировать целиком сразу, он выполнит:
- переименование скрипта mount
- создание нового скрипта mount
- установку прав на запуск
mv /bin/mount /bin/mount.bin cat >> /bin/mount << EOF #!/bin/sh if echo \$@ | grep "btrfs" >/dev/null; then /bin/mount.bin \$@ -o compress=lzo else /bin/mount.bin \$@ fi EOF chmod 755 /bin/mount
Вот собственно и всё. Потом устанавливаем ОС, выбрав для разделов btrfs. Сразу после установки (не перегружаясь) нужно добавить опции монтирования со сжатием - compress=lzo в fstab только что установленной системы (который будет находиться в /target/etc/fstab).
btrfs и GRUB
В состав GRUB входят драйвера btrfs. Однако это очень урезанный драйвер и он не поддерживает запись. А отсутствие записи не позволяет GRUB-у записать служебную переменную recordfail. GRUB проверяет значение этой переменной и если она не сброшена, то обязательно показывается меню загрузки. Каждый раз когда GRUB начинает загружать ОС он устанавливает эту переменную в 1, а сбрасывает ее скрипт который запускается после загрузки системы.
Т.к. сохранить значение recordfail GRUB на btrfs не может, то он считает, что каждая загрузка происходит после фейла прошлой загрузки (т.е. recordfail=1). И в таком случае меню загрузки показывается 10 или даже 30 секунд. Изменить этот тайм-аут можно изменив в /etc/default/grub значение переменной GRUB_RECORDFAIL_TIMEOUT. После задания разумного таймаута в /etc/default/grub нужно запустить update-grub с правами root-а чтобы пересоздать скрипты загрузки GRUB-а.
swap файл на btrfs
Начиная с версии ядра 5.0+ на btrfs можно создать swap-файл, но с некоторыми ограничениями: swap-файл должен располагаться целиком на одном устройстве 7), создаваться обязательно с отключенным COW и сжатием8). Кроме того swap-файл не может попасть в снимок9). В перспективе предполагается снять часть ограничений.
С учетом озвученного, пока не сняты ограничения, swap-файл стоит создавать в отдельном (специально для него созданном под-томе).
Предположим что у нас btrfs на одном устройстве и у нас подходящая версия ядра 5.0+, дальше все довольно просто:
btrfs su cr /swap # создаем отдельный под-том touch /swap/swap # создаем пустой файл /swap - COW можно отключить только на пустом файле chmod go-r /swap/swap # swap должен иметь права 600, а touch проставляет права 644 chattr +C /swap/swap # отключаем COW (сжатие тоже отключается при отключении COW) fallocate /swap/swap -l4g # выделяем место под файл 4Gib mkswap /swap/swap # создаем внутреннюю разметку в файле для swap-а swapon /swap/swap # подключаем swap
Для автоматического монтирования файла в последующем нужно в /etc/fstab добавить следующую строку:
/swap/swap none swap sw 0 0
До версии 5.0 использование swap-файла на btrfs могло привести к разрушению структуры файловой системы (отключение COW и компрессии не помогало избежать проблем) и поэтому драйвер не дает активировать своп в swap-файле созданном на btrfs. Можно было создать не очень быстрый и с дополнительными расходами оперативной памяти10) swap-файл через loop-устройство. Давайте рассмотрим пример создания своп-файла этим методом.
Несмотря на то, что отключение COW не помогает, но для избежания фрагментации swap-файла на HDD (на SSD это не так критично) стоит все-таки отключить COW. Компрессию тоже стоит отключать т.к. это еще сильнее затормозит и без того не быстрое решение.
touch /swap # создаем пустой файл /swap - COW можно отключить только на пустом файле chmod go-r /swap # swap должен иметь права 600, а touch проставляет права 644 chattr +C /swap # отключаем COW (сжатие тоже отключается при отключении COW) fallocate swap -l4g # выделяем место под файл размером 4Gib swapfile=$(losetup -f) # находим первое свободное loop-устройство losetup $swapfile /swap # настраиваем доступ к файлу /swap через loop-устройство mkswap $swapfile # создаем внутреннюю разметку для swap-а на loop-устройстве swapon $swapfile # подключаем swap
Для подключения такого swap после перезагрузки добавьте код начиная с swapfile=$(losetup -f) в файл /etc/rc.local (до строки exit 0).
Обслуживание btrfs
Как и любая другая ФС, btrfs может работать много лет, не требуя какого-то особого обслуживания, однако мы озвучим те действия, которые полезно периодически проводить для поддержания «здоровья» btrfs.
Один из явных симптомов того, что btrfs требует обслуживания - медленная загрузка системы (допустим, ранее система грузилась за минуту, а в последнее время загрузка продолжается 3-5 минут).
Если в fstab указаны опции монтирования inode_cache и space_cache, лучше их выключить, затем примонтировать раздел с параметром clear_cache
mount -o clear_cache /dev/sda1 /mnt
Стандартные действия по обслуживанию - дефрагментация (наводим порядок в данных) и балансировка (наводим порядок в метаданных):
sudo btrfs filesystem defrag /mnt sudo btrfs balance start /mnt
Узнать подробности о состоянии файловой системы ftrfs можно командой:
btrfs check --force --readonly /dev/<раздел на котором расположена btrfs>
тут –force используется для того, что бы подавить ошибку запуска утилиты на уже смонтированном разделе, но не надо опасаться - по умолчанию btrfs check выполняется в режиме только чтения (ключ –readonly указан тут чисто для душевного спокойствия).
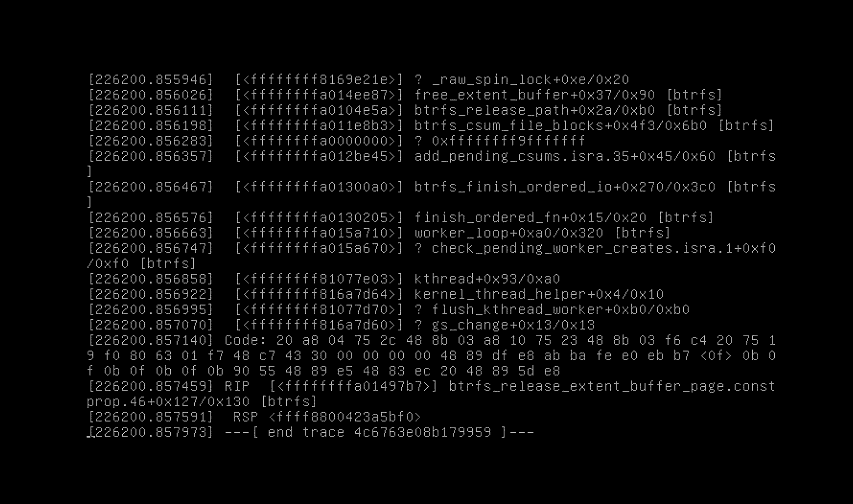
Если возникают критические проблемы с fs (при загрузке выдаётся нечто подобное), то переходим к разделу «Восстановление btrfs».
Еще полезно периодически запускать пересчет контрольных сумм (btrfs crub). В процессе работы (особенно если выключать компьютер по питанию, а не через shutdown) контрольные суммы могут потерять свою актуальность. Поэтому периодически запускать их пересчет - не такая и плохая идея. А нужно ли вам запускать пересчет контрольных сумм можно узнать из проверки файловой системы командой:
btrfs check --check-data-csum --force --readonly /dev/<раздел на котором расположена btrfs>
Восстановление btrfs
Как и многие современные файловые системы btrfs при монтировании тома автоматически проверяет целостность файловой системы и если обнаруживаются какие-то проблемы, то драйвер btrfs пытается их устранить автоматически. Однако не любая проблема может быть решена без дополнительно вмешательства человека. Если btrfs не удастся смонтировать, то придется брать ситуацию в свои руки. Попробуем описать возможные пути исправления этой ситуации.
Первым делом..
Самым первым делом полезно взглянуть на SMART данные диска - все ли с ним в порядке или он начал «сыпаться»? Если диск «не здоров», то нужно найти необходимое место для создания полной резервной копии с такого носителя и сделать эту резервную копию командой dd с опцией noerror.
Если диск «здоров», то все равно стоит сделать резервную копию, но для удобства можно делать резервную копию только метаданных (ведь именно их мы будем «чинить»). Резервную копию метаданных стоит сделать и с образа, снятого с умирающего диска. Копия метаданных позволит нам восстановить начальной состояние ФС в случае, если наши попытки починить ее только усугубили положение11).
Сделать копию метаданных btrfs можно, используя специальную утилиту btrfs-image:
btrfs-image <имя раздела с btrfs> <файл куда сохранить>
В дальнейшем, если мы зашли в тупик с восстановлением btrfs, можно применить эту же утилиту с ключом -r и тем самым вернуть btrfs к начальному состоянию (порушенному, но без нашего вмешательства).
После того, как мы убедились, что с диском все в порядке или сделали образ с «посыпавшегося» диска, можно приступать непосредственно к восстановлению. Для начала нужно решить, что вам нужно от поврежденного раздела. Если у вас на разделе хранилось небольшое количество ценных файлов, а все остальное для вас не представляет ценности, то можно вытащить отдельные файлы утилитой btrfs restore, если же ценность представляет весь раздел, то нужно воспользоваться другими инструментами, которые помогут вернуть к жизни весь раздел.
Восстановление данных с раздела btrfs
Для того, чтобы вытащить данные с поврежденного раздела, можно воспользоваться утилитой btrfs restore. Утилита заявлена как «неразрушающая (non-destructive)» и работает с отмонтированным носителем. Синтаксис:
btrfs restore <ключи запуска> <раздел> <путь для сохранения>
Для восстановления как можно более полной информации с поврежденного раздела, следует указать команду так:
btrfs restore -sxmSo <раздел> <путь для сохранения>
Ключи запуска утилиты следующие:
-s|--snapshots # получить снимки
-x|--xattr # получить расширенные атрибуты
-m|--metadata # восстановить метаданные (владелец, время)
-S|--symlinks # восстановить символьные ссылки
-v|--verbose # подробный вывод
-i|--ignore-errors # игнорировать ошибки (Как правило, утилита останавливает свою работу
# при возникновении какой-либо ошибки. Этот ключ позволяет утилите
# принудительно продолжить восстановление)
-o|--overwrite # перезаписывать файлы (Без этого ключа утилита пропускает восстановление
# файла, если он уже присутствует в месте назначения)
Подробный вывод (ключ -v), как правило, не представляет интереса. О любой исключительной ситуации будет немедленно оповещено. За более полным описанием ключей следует обратиться к инструкции btrfs restore или на https://btrfs.wiki.kernel.org/index.php/Restore.
Восстановление раздела btrfs
Для начала попробуем смонтировать btrfs в режиме восстановления (т.е. попросим btrfs попытаться восстановиться самостоятельно)
mount -o recovery <имя раздела с btrfs> <путь куда монтируем>
Если это не поможет, то смотрим dmesg на предмет ошибок при монтировании. Если возникли ошибки с деревом журнала (log tree) или лог повреждён, то пробуем обнулить лог12).
btrfs rescue zero-log <имя раздела с btrfs>
Если в dmesg упоминаются ошибки с деревом чанков (chunk tree), например, есть сообщения вида «can't map address», то поможет команда chunk-recover утилиты восстановления.
btrfs rescue chunk-recover <имя раздела с btrfs>
Если в ошибках упоминается суперблок, то можно попытаться восстановить первичный суперблок из его «здоровой» копии (поиск «здоровой» осуществляется автоматически). Это попытается сделать команда
btrfs rescue super-recover <имя раздела с btrfs>
Утилиту btrfsck (она же btrfs check) стоит пробовать в последнюю очередь - это уже «тяжелая артиллерия» в борьбе с ошибками btrfs.
btrfs check --readonly <имя раздела с btrfs>
Это даст более подробное представление о состоянии раздела.
Ключи -s1, -s2, -s3 - будут пытаться скопировать на место первичного супер-блока его резервные копии (возможно, более работоспособные). Действие аналогично запуску btrfs rescue super-recover, однако вы сами выбираете, какую копию суперблока использовать.
Ключ --init-extent-tree поможет, если повреждено дерево экстентов (extent tree).
Ключ --init-csum-tree создаст новое дерево контрольных сумм и пересчитает их для всех файлов.
Ключ --repair запускает режим восстановления и пытается исправить существующие проблемы.
Если ничего не помогло, и раздел btrfs продолжает отказываться монтироваться, то, видимо, стоит смириться с потерей раздела, но есть ещё шанс вытянуть важные файлы (как это сделать, описано в предыдущей главе).
Другие советы по использованию
Время от времени запускайте балансировку для профилактики. Журнал и метаданные (особенно в более старых версиях ФС) имеют свойство сильно разрастаться, в результате чего Вы будете видеть, что свободного места хоть отбавляй, а по факту - при попытке записать файл, обновить систему вы получите ошибку No space left on device. Для устранение которой придется где то искать дополнительный носитель, для того что бы расширить существующую ФС на него или перенести часть файлов.
Можно спокойно использовать любые опции при монтировании, но разумным будет использовать набор space_cache, compress, autodefrag. Первая призвана уменьшить количество операций чтения и записи, вторая обеспечивает сжатие для уменьшения объёма передаваемых данных, autodefrag - для фоновой дефрагментации при обнаружении сильно фрагментированных файлов.
Драйвер BTRFS автоматически определяет, что btrfs-раздел создан на SSD, и также автоматически включает все необходимые ключи (опция ssd) для эффективной работы на этом типе носителя.
Подробнее о контроле времени доступа см. Relatime
— nefelim4ag 2012/09/07 22:42
Вообще обращайтесь если будут вопросы, по возможности помогу с этой фс nefelim4ag@gmail.com
— sly_Tom_Cat
Давно использую и много экспериментирую с btrfs. Чем смогу - помогу slytomcat@mail.ru

{kind=link}